
目录
概念
-
ZooKeeper 是分布式应用程序的分布式开源协调服务。命名空间的组织方式类似于标准文件系统,运行在JAVA环境中。
-
数据保存在内存中,可实现高吞吐量和低延迟。
-
内存中维护状态图像

- 数据模型和分层命名空间
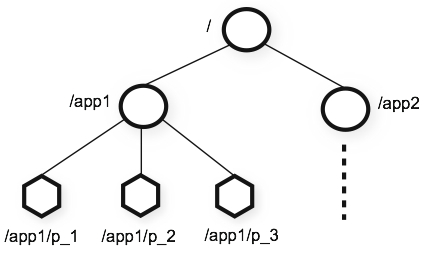
与标准文件系统不同,ZooKeeper 命名空间中的每个节点都可以拥有与其关联的数据以及子节点。这就像拥有一个允许文件也成为目录的文件系统。(ZooKeeper 被设计用来存储协调数据:状态信息、配置、位置信息等,所以每个节点存储的数据通常很小,在字节到千字节的范围内。1M)我们使用术语znode来明确我们正在谈论 ZooKeeper 数据节点。
节点
-
持久节点
- Znode 维护一个统计结构,其中包括数据更改、ACL 更改和时间戳的版本号,存储在命名空间中每个 znode 的数据是原子读取和写入的
-
临时节点
- 只要创建 znode 的会话(session)处于活动状态,这些 znode 就存在。当会话结束时,znode 被删除。
-
序列节点
- create -s xx00000001 xx00000002
有条件的更新和监视
- ZooKeeper支持 watch 的概念。客户端可以在 znode 上设置监视。当 znode 发生变化时,watch 将被触发并移除。当 watch 被触发时,客户端会收到一个数据包,说明 znode 已更改。如果客户端和其中一个 ZooKeeper 服务器之间的连接断开,客户端将收到本地通知。
- **3.6.0 中的新功能:**客户端还可以在 znode 上设置永久的递归监视,这些监视在触发时不会被删除,并且会以递归方式触发已注册 znode 以及任何子 znode 上的更改。
保证
- 顺序一致性 - 来自客户端的更新将按照它们发送的顺序应用。(写命令都转到leader节点)
- 原子性 - 更新成功或失败。没有部分结果。
- 单一系统映像 - 客户端将看到相同的服务视图,而不管它连接到的服务器如何。即,即使客户端故障转移到具有相同会话的不同服务器,客户端也永远不会看到系统的旧视图。
- 可靠性 - 应用更新后,它将从那时起持续存在,直到客户端覆盖更新。
- 及时性——系统的客户视图保证在一定的时间范围内是最新的。
API
- create : 在树中的某个位置创建一个节点
- delete : 删除一个节点
- exists : 测试节点是否存在于某个位置
- get data : 从节点读取数据
- set data : 将数据写入节点
- get children : 检索节点的子节点列表
- sync : 等待数据传播
执行
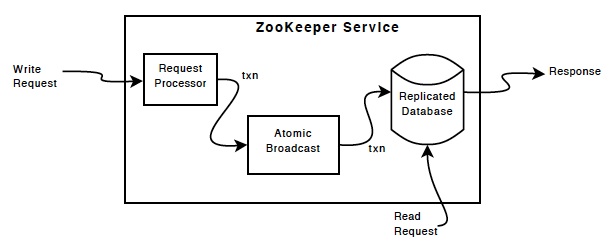
ZooKeeper 服务的每个服务器都复制自己的每个组件的副本
-
复制数据库是包含整个数据树的内存数据库。更新被记录到磁盘以便恢复,写入在应用到内存数据库之前被序列化到磁盘。
-
每个 ZooKeeper 服务器都服务于客户端。客户端仅连接到一台服务器以提交请求。从每个服务器数据库的本地副本为读取请求提供服务。改变服务状态的请求,写请求,由协议协议处理。
-
客户端所有写请求都转发由 leader 服务器处理。 ZooKeeper 服务器的其余部分,称为追随者,接收来自领导者的消息提议并同意消息传递。消息传递层负责在失败时替换领导者并将追随者与领导者同步。
-
ZooKeeper 使用自定义原子消息传递协议。由于消息传递层是原子的,ZooKeeper 可以保证本地副本永远不会发散。当领导者收到一个写请求时,它会计算系统在应用写时的状态,并将其转换为捕获这个新状态的事务。
安装笔记
zk集群至少 三台节点,少于三台集群将不可用
1.安装jdk,并设 JAVA_HOME
2.下载 zookeeper https://zookeeper.apache.org/releases.html
3.解压后移动到/opt目bian
4.设置环境变量 ZOOKEEPER_HOME
5. cp zoo sample.cfg zoo.cfg
6. zoo.cfg 中
#服务心跳间隔 2秒
tickTime = 2000
#初始化次数 最大允许等待 2000 * 10 = 20秒
initLimit = 10
#主从同步次数 2000 * 5 = 10秒 未同步 认为失败
syncLimit = 5
#持久化目录
dataDir = /var/下
#客户端连接端口号
clientPort=2181
#server.X的条目列出了组成 ZooKeeper 服务的服务器。
#服务器启动时,通过在数据目录中查找文件myid来知道它是哪个服务器。该文件包含 ASCII 格式的服务器编号。
#2888 追随者连接到领导者通信(有leader情况下)
#3888 投票选举leader(无leader)
server.1=zoo1:2888:3888
server.2=zoo2:2888:3888
server.3=zoo3:2888:3888
7. 启动
zkServer.sh {start start-foreground stop restart status upgrade print-cmd}
8. 连接
zkCli.sh --server ip:port
> help
create 无参 非顺序的也就是没有顺序的并且是持久化的 -e 创建临时节点 -s 顺序节点
9. netstat -natp | egrep '(2888|3888)'
10. jps 查看zk 是否启动
11 zkServer.sh status 查看运行状态
observer 模式
问题:随着添加更多投票成员,写入性能下降。因为写入操作需要(通常)集成中 至少一半节点 的协议,因此随着更多选民的加入,投票的成本会显着增加。
observer模式 不参与投票,只遵循投票结果 ,其余功能与追随者完全相同
配置文件中:
peerType=observer
server.1:localhost:2181:3181:observer
zookeeper全解析Paxos
灵魂 基于消息传递的一致性算法
ZAB协议
-
原子:成功 失败 没有中间状态(队列+2PC)
-
广播:分布式节点的,不一定全部都知道
-
队列:FIFO 顺序性

zookeeper选举过程
- 3888端口 两两通讯
- 只要任何人投票,都会触发那个准 leader发起自己的投票
- 推选制:先比较zxid,如果zXid相同,再比较myid
Watch
-
Created event: Enabled with a call to exists.
-
Deleted event: Enabled with a call to exists, getData, and getChildren.
-
Changed event: Enabled with a call to exists and getData.
-
Child event: Enabled with a call to getChildren.

使用场景
-
分布式配置中心 watch

-
分布式锁
-
个客户端争抢锁,只有一个人能获得锁
-
获得锁的人出问题怎么办 ,可以用 临时节点( session)解决
-
获取锁的人怎么释放锁?锁被 释放 删除 别人怎么知道
-
主动轮询,心跳。。。弊端:延迟,压力
-
watch:解决延迟问题。。弊端:压力(会唤醒所有客户端争抢锁, 惊群现象)
-
可使用 sequence +watch 序列节点
watch谁呢? 每个序列节点 watch 前一个节点, 最小的节点先获取锁,最小节点是否锁后 只会回调下一个节点,避免了惊群现象!
-